

The field of Visual Intelligence is continuously transforming. Chief Research Scientist Arnt-Børre Salberg dives deeper into the current trends in the field of visual intelligence as of early 2026.
The field of Visual Intelligence is continuously transforming. Chief Research Scientist Arnt-Børre Salberg dives deeper into the current trends in the field of visual intelligence as of early 2026.
By Arnt-Børre Salberg, Chief Research Scientist at Visual Intelligence and the Norwegian Computing Center
While previous years were influenced by the emergence of Large Language Models (LLMs), generative models, and multi-modal capabilities, the current landscape is increasingly expanding toward specialized foundation models for the physical world, efficient 3D representations, and sophisticated AI agents.
Foundation models (FMs) are expanding beyond text and general images into complex scientific domains. A major trend is the development of domain specific multi-modal FMs, like for Earth observation (EO) and weather forecasting.
Aurora [Bodnar et al., 2025] represents a leap for Earth system forecasting. Pretrained on over one million hours of diverse data like ERA5 and CMIP6 climate simulations, it uses a 3D Perceiver encoder to ingest heterogeneous variables at any resolution. This 1.3-billion-parameter FM employs a 3D Swin Transformer backbone to outperform operational systems in predicting air quality, tropical cyclone tracks, and 0.1° high-resolution weather at a fraction of the computational cost.
Aardvark Weather [Allen et al., 2025] focuses on a fully end-to-end approach, ingesting raw observations like satellite and station data directly to produce forecasts in roughly one second on GPUs, a massive speedup compared to the 1,000 node-hours required by traditional systems. Together, these models demonstrate that AI can deliver high-fidelity global and local predictions without the resource-heavy reliance on traditional numerical solvers at deployment time.
Within EO, the FM TerraMind [Jakubik et al., 2025] demonstrates superior benchmark performance, but also generative capabilities. New models like THOR [Forgaard et al, 2026] (developed by NR and UiT) is a flexible, multi-sensor model for EO that unifies Sentinel-1 SAR, Sentinel-2 MSI, and Sentinel-3 OLCI & SLSTR data from 10 m - 1000 m GSD, built on a compute-adaptive vision transformer backbone. This enables the use of smaller patch sizes at inference, providing a denser token sequence that is more effective for fine-tuning on limited data.
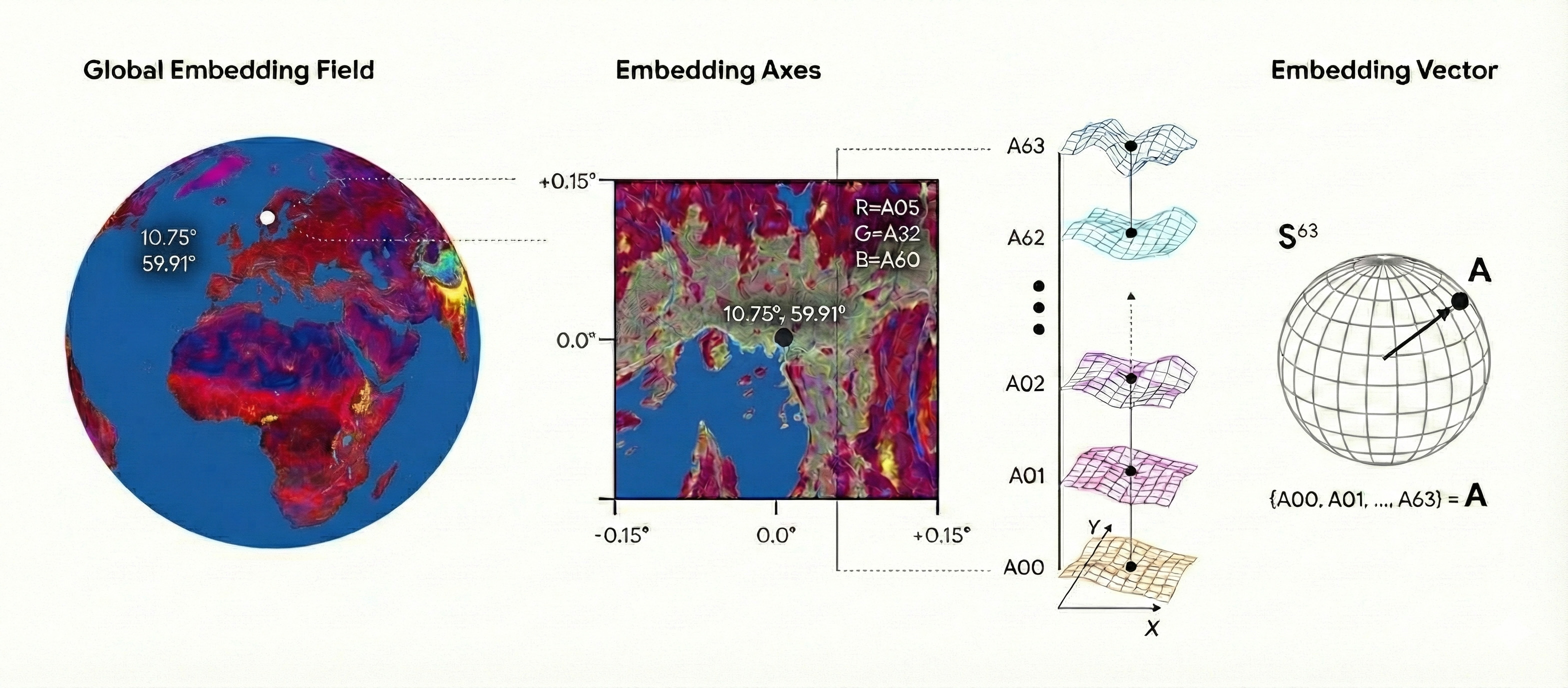
However, one of the largest breakthroughs within EO is Google’s AlphaEarth Foundations [Brown et al., 2025], providing a dense Earth embeddings of 64-element features vectors in a 10 m grid with global coverage, monthly temporal resolution, and accessible via Google Earth Engine. The embedding is created by integrating data from various sources, including satellite images, radar, 3D laser mapping, and climate models.
3D vision is experiencing a revolution fueled by AI, moving from iterative optimization to direct prediction. New architectures like the Visual Geometry Grounded Transformer (VGGT ) [Wang et al., 2025] can directly infer key 3D attributes, such as camera parameters and depth maps, from just a few views. Another interesting direction is 3D Gaussian Splatting, a technique that creates photorealistic scenes by modeling them as a set of 3D anisotropic Gaussians. This method supports complex view-dependent effects and enables real-time rendering for VR and AR, surpassing traditional point clouds by better capturing fine-grained geometric details and surface textures.
Researchers are also integrating these techniques into multimodal pre-training. For example, UniGS (Unified Language-Image-3D Pretraining with Gaussian Splatting) [Li et al., 2025] enhances 3D representations by aligning them with text and image encoders via a Gaussian-aware guidance module, enabling tasks like zero-shot classification and text-driven retrieval in 3D scenes.
Diffusion models remain a cornerstone of generative AI, but their architectures is evolving. We are seeing a shift from traditional U-Nets to Diffusion Transformers [e.g., Peebles & Xie, 2023], where self-attention mechanisms, often optimized for scale, capture the global context necessary for coherent high-resolution generation. Efficiency is also a priority, with techniques like distillation and rectified flows reducing the number of steps required for generation of content.
Beyond diffusion, Visual Autoregressive Modeling [Tian et al., 2025] is emerging as a scalable alternative. Unlike traditional next-token prediction, VAR generates images via "next-scale prediction," building the image from low to high resolutions in a coarse-to-fine manner.
In robotics, Navigation World Models [Bar et al., 2025] represent a shift from fixed policies to predictive planning. These models allow robots to hallucinate future visual observations based on proposed actions, enabling them to simulate paths in novel environments from a single input image. Crucially, they support test-time conditioning, meaning users can dynamically impose new constraints (e.g., 'avoid the wet floor') without retraining.

One of the most promising frontiers is the development of AI Agents, autonomous systems capable of perceiving their environment, reasoning, and acting to achieve goals without constant human input. A prime example is Claude Code, an agentic command-line interface (CLI) that allows developers to interact with the model directly in their terminal to automate software development. It understands local file structures, can read/edit files, run terminal commands, manage git operations, and solve complex debugging tasks through natural language prompts. Beyond the terminal, 2025 has introduced “Computer use” capabilities (e.g., OpenAI Operator), enabling agents to visually navigate desktop GUIs and web browsers like a human.
Fueled by AI Agents we have seen also seen the rise of “vibe coding”. Natural language interfaces are lowering the barrier to software creation, enabling non-developers to build tools by describing what they want. Framework like Lovable (and Claude Code) could fundamentally change who builds new software and how fast.
As the demand for data grows, synthetic data is becoming indispensable. It serves as a proxy for real-world data, addressing privacy concerns and the high cost of labeling. Gartner predicts that by 2030, synthetic data will completely overshadow real data in AI models.
Finally, as these technologies mature, Trustworthy AI remains critical. The focus is shifting from "black box" models to explainable frameworks and models that quantify their uncertainty, ensuring transparency in decision-making. Addressing algorithmic bias and ensuring data privacy through governance frameworks like GDPR and the EU AI Act are essential steps to maintain human oversight and trust in high-stakes applications.
Allen, A., Markou, S., Tebbutt, W., Requeima, J., Bruinsma, W. P., Andersson, T. R., ... & Turner, R. E. (2025). End-to-end data-driven weather prediction. Nature, 641(8065), 1172-1179.
Bar, A., Zhou, G., Tran, D., Darrell, T., & LeCun, Y. (2025). Navigation world models. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 15791-15801).
Bodnar, C., Bruinsma, W. P., Lucic, A., Stanley, M., Allen, A., Brandstetter, J., ... & Perdikaris, P. (2025). A foundation model for the Earth system. Nature, 1-8.
Brown, C. F., Kazmierski, M. R., Pasquarella, V. J., Rucklidge, W. J., Samsikova, M., Zhang, C., ... & Kohli, P. (2025). AlphaEarth foundations: an embedding field model for accurate and efficient global mapping from sparse label data. arXiv preprint arXiv:2507.22291.
Forgaard, T., Reksten, J. H., Waldeland, A. U., Marsocci, V., Longépé, N., Kampffmeyer, M., & Salberg, A. B. (2026). THOR: A Versatile Foundation Model for Earth Observation Climate and Society Applications. arXiv preprint arXiv:2601.16011.
Jakubik, J., Yang, F., Blumenstiel, B., Scheurer, E., Sedona, R., Maurogiovanni, S., ... & Longépé, N. (2025). Terramind: Large-scale generative multimodality for earth observation. arXiv preprint arXiv:2504.11171.
Li, H., Zhou, Y., Tang, T., Song, J., Zeng, Y., Kampffmeyer, M., ... & Liang, X. (2025). Unigs: Unified language-image-3d pretraining with gaussian splatting. arXiv preprint arXiv:2502.17860.
Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 4195-4205).
Tian, K., Jiang, Y., Yuan, Z., Peng, B., & Wang, L. (2024). Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in neural information processing systems, 37, 84839-84865.
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., & Novotny, D. (2025). VGGT: Visual geometry grounded transformer. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 5294-5306).

Visual Intelligence hosted over 45 international AI researchers for the DL2026 workshop at UiT The Arctic University of Norway.

Visual Intelligence will be well represented at MICCAI 2026, one of the leading AI conferences on medical imaging and computer assisted intervention, with two accepted research papers.

Visual Intelligence co-organized and attended the "Foundations of Arctic AI and Generative Forecasting": an inaugural workshop in the P1 Arctic AI program.

PhD Candidates Solveig Thrun and Christian Salomonsen attended the Datacloud Global Congress' Talent in Tech programme, which invited emerging talent to a unique programme designed to inspire, educate, and connect young professionals with senior leaders from global tech giants.

We warmly welcome Georgios Leontidis as a new Professor at SFI Visual Intelligence's hub at UiT The Arctic University of Norway.

Centre Director Robert Jenssen was interviewed by Norsk rikskringkasting (NRK) about the Japan-Norway AI Innovation Forum in Tokyo, Japan.

En ny AI-løsning utviklet ved UiT kan gjøre det enklere å avdekke feilrapportering og ulovlig fiske. Nå skal Norges Råfisklag teste teknologien i praktisk bruk (News article on kystogfjord.no)

Principal Investigator Kristoffer Wickstrøm was interviewed by Norsk rikskringkasting (NRK) about the Artificial Intelligence Day at UiT- The Arctic University of Norway.
.jpg)
En ny, åpent tilgjengelig KI-modell kan endre hvordan geologer tolker seismikk. Den norske grunnmodellen lover raskere analyser, lavere terskel for innovasjon og nye måter å forstå undergrunnen på.
Centre Director Robert Jenssen was interviewed by Norsk rikskringkasting (NRK) about AI in fisheries and this year's UArctic (University of the Arctic) Congress on the Faroe Islands.
.jpg)
Professor and AI expert Robert Jenssen is attending the Japan-Norway AI Innovation Forum and Japan-Norway Research Symposium, two high-level meetings with Norwegian and Japanese government leaders, business actors and researchers.

Visual Intelligence researchers Solveig Thrun and Kristoffer Wickstrøm took their research out of the lab and to Tromsø city centre as part of Pint of Science 2026.

Subsurface Digital Manager and former Visual Intelligence board member Cathrine Tegnander will serve as the elected leader of Visual Intelligence's board.

The Call for Papers and Abstracts for the Northern Lights Deep Learning (NLDL) Conference 2027 is officially announced – with submission deadlines on August 7th and Mid-September 2026 respectively.

Generativ kunstig intelligens er imponerende, men ikke alltid så nyttig til å løse industrielle problemer (Norwegian op-ed in digi.no).

Congratulations to Marit Dagny Kristine Jenssen, who successfully defended her PhD thesis at UiT The Arctic University of Norway on April 10th

The NCS model, a seismic foundation model trained on data from the Norwegian data repository for subsurface data, is now available as an open-source model, allowing anyone to download, utilize, and further develop the model.

The Visual Intelligence Annual Report 2025, highlighting the centre's progress, activities, achieved innovations, staff, funding, and publications for 2025, is now available to read on our websites.
.jpg)
Congratulations to Centre Director Robert Jenssen, who received UiT's Research and Development Award at the university's annual celebration.

Visual Intelligence researchers contributed to the Pioneer Centre for AI workshop on Electronic Health Records research. The aim was to strengthen ties between the two centres on EHR-related research.